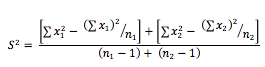
| TOPICO | ANALISIS ESTADISTICO BASICO |
| TIEMPO APROXIMADO | 45 MINS. |
| AUDIENCIA | METODO DE INVESTIGACION Y BIOESTADÍSTICA, FAC. ODONTOLOGÍA, U. MAYOR |
| INSTRUCTORES | Dr. Benjamín Martínez R. |
| Dra. Daniela Albers. |
- I. Racional.
- II. Objetivos Terminales.
- III. Objetivos Específicos.
- IV. Test Inicial.
- Ciclo de Práctica I.
- Ciclo de Práctica II
- Ciclo de Práctica III
- Ciclo de Práctica IV
- Ciclo de Práctica V
- V. Test Final
I. RACIONAL:
El análisis estadístico apropiado de una investigación es fundamental para obtener conclusiones válidas. La mayoría de los investigadores no utilizan el análisis adecuado para el estudio que realizan. Según Glantz (Circulation 61:1-7,1980) en 142 artículos publicados en Circulation, sólo un 34% utilizaron el análisis estadístico correcto.
II. OBJETIVOS GENERALES:
Conocer e interpretar algunos tests estadísticos y mediciones básicasen estadística descriptiva.
III. OBJETIVOS TERMINALES:
El alumno podrá determinar:
media, desviación estandard, percentiles, calcular el valor de t, chi cuadrado, Anova, e interpretar el significado de dichos tests.
CICLO DE PRACTICA I.
GENERALIDADES:
MEDIDAS DE RESUMEN
Las medidas descriptivas se utilizan con el fin de resumir los datos, las que se calculan a partir de los datos de una muestra se conocen como estadística. Existen dos tipos de medidas, clasificándose de acuerdo a su posición o según su dispersión. Las medidas de posición buscan el centro de la serie o valores que mantengan una posición fija dentro de la serie. Las medidas de tendencia central son: el promedio, la mediana y el modo. Los puntos de posición dentrode la serie corresponden a los llamados percentiles.
El promedio o media corresponde a un punto único dentro de la serie, que representa el centro de equilibrio de ésta. El promedio se obtiene mediante la suma de los valores de x dividida por el número de casos n. El problema de esta medida de resumen es que es muy afectada por valores extremos; cualquier valor que se aleje de la serie afecta la simetría de la curva y arrastra al promedio. La mediana es el punto que divide a la serie en dos mitades iguales, cuando la serie está ordenada. Nos divide a la curva en dos áreas iguales y tiene la ventaja de no ser afectada por la asimetría. El modo o moda es el valor alrededor del cual los datos tienden a agruparse. Es el valor o losvalores que más se repiten, puede corresponder a más de unpunto de la curva.
Sin importar el método que se use (promedio o mediana) para ubicar el centro de los datos, es importante la variabilidad. Específicamente, nos interesa saber cómo, en qué rango de valores, se agrupan los datos, como también qué tan cerca está cada dato del centro de la curva. Un método muy útil es determinar el percentil 25 (P25) y el percentil 75 (P75). De todos los valores considerados, el 25% cae bajo P25 y el 75% se encuentra bajo P75. El rango intercuartil se extiende desde el valor de P25 hasta el valor de P75, e incluye el 50% de los datos. El gráfico de cajas permite apreciar en forma clara estos distintos percentiles, el que puede realizar con algunos softwares, tales como Systat.
La dispersión de un conjunto de observaciones se refiere a la variación que exhiben los valores de las observaciones. Si todos los valores son iguales, no hay dispersión; si no todos son iguales, hay dispersión en los datos. Dentro de las medidas de dispersión tenemos: la amplitud, la varianza, la desviación estandar, y la desviación intercuartílica. Cuando tenemos sets de datos muy pequeños, la variabilidad puede mostrarse mediante la amplitud, recorrido o rango, dado por el valor más chico y el más grande. Sin embargo, la desventaja del rango es que depende en gran medida del número de casos n, generalmente al incluir más casos, el rango se amplia. La amplitud es la diferencia entre el valor máximo y mínimo de la serie.
Cuando los valores de un conjunto de observaciones están muy próximos a su media, la dispersión es menor que cuando están distribuídos sobre un amplio recorrido. La medida de la dispersión de los valores con respecto a la media corresponde a la varianza. Cómo calcularla:
- Se resta el promedio a cada uno de los valores.
- Se elevan al cuadrado las diferencias.
- Se suman.
- Se divide la suma por el tamaño de la muestra menos 1.
La varianza representa unidades cuadradas, no siendo una medida de dispersiónapropiada cuando se desea expresar este concepto en términos de las unidades originales. Para ello utilizamos la desviación estándar, que corresponde a la raíz cuadrada de la varianza.
Ejemplo:
1.
| Datos | Desviación desde el promedio |
Desviación al cuadrado |
| -2 | 4 | 16 |
| 0 | 2 | 4 |
| +2 | 0 | 0 |
| +4 | 2 | 4 |
| +6 | 4 | 16 |
2. Suma de las desviaciones al cuadrado : Σ(x – xi2) = 40
3. (n = 5)
4.
![]()
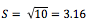{kind=link}
![]()
s: desviación estándar de una muestra, y es igual a la raíz cuadrada de la varianza.
Para obtener la desviación estandar de dos grupos utilizamosla siguiente fórmula:
1. Cálculamos la varianza común.

-
- Σx1 = sumatoria de los valores del grupo 1
- Σx12 = sumatoria de los valores al cuadrado del grupo 1
- (Σx1)2 = sumatoria de los valores del grupo 1 y luego el total elevado al cuadrado
- n1 = número de observaciones en el grupo 1
2. Calculamos la desviación estandar, que es la raíz cuadrada de la varianza.
![]()
Referencias bibliográficas
- O´Brien PC., Shampo MA. Statistics for Clinicians. Mayo Clin. Proc. 56:45-49, 1981.
- Glantz SA. Primer of Biostatistics. 3rd ed. McGraw Hill, New York, 1992:11.
Retroalimentación:
1. ¿Cuáles son las medidas de resumen de tendencia central?
2. ¿Qué porcentaje de casos se ubican entre el percentil 33 (P33)y el percentil 66 (P66)?
a) 50%
b) 33%
c) 66%
d) 99%
3. Calcule la desviación estandar de las notas obtenidas por un alumno en Anatomía: 4.5, 3, 4, 5.5, 2.5, 7.
CICLO DE PRACTICA II
DISTRIBUCION NORMAL
Gran parte de la teoría estadística para la prueba de hipótesis se basa en la distribución normal. La distribución normal es también llamada curva de error o campana de Gauss. Existen factores biológicos que siguen o calzan con esta distribución matemática. La distribución normal describe la distribución de probabilidad de una variable aleatoria continua, como la variación biológica de algunas variables: altura, peso, glicemia, pulso y niveles de colesterol. Imaginemos una curva de distribución normal, ella estará centrada en un promedio m, y su dispersión estará dada por una desviación estandar s.
Los siguientes puntos son las características más importantesde la distribución normal.
-
- La distribución normal es simétrica alrededor del promedio.
- Promedio, mediana y modo son iguales.
- El área total bajo la curva arriba del eje de las x es una unidad de área, donde el 50% del área está hacia la derecha de una perpendicular trazada en el promedio y el 50% restante hacia la izquierda.
- El área total a una desviación estándar del promedio es 68%, a dos 95% y a tres 99.7%.
- La distribución normal está determinada completamente por los parámetros m y s.
- Las letras griegas m y s ese utilizan para la curva de la población y en una muestra se utiliza x (para el promedio con una barra horizontal sobre ella y DS para la desviación estándar).
La distribución normal estándar, comúnmente denotada por z, tiene un promedio igual a 0 y una desviación estándar igual a1.
Para calcular un área bajo la distribución normal, los valores son convertidos a la escala z. Si la variable tiene un promedio m y desviación estándar, entonces para convertir un valorde x a su correspndiente z, se utiliza la siguiente fórmula:
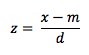 Esto expresa un valor x como un número específico de unidadesde desviaciones estandar del promedio m.
Esto expresa un valor x como un número específico de unidadesde desviaciones estandar del promedio m.
Es necesario antes de proceder con análisis estadístico de variables intervalares determinar si éstas tienen distribución normal, para esto existe el test de Shapiro-Wilks, y otros. Además de algunos gráficos disponibles en varios softwares (ver en Systat, Stata, u otors). En caso de no disponer de ninguno de los anteriores, debe ser altamente sospechoso que sus datos NO tienen distribución normal si la desviación estándar es mayor que el promedio. En caso de que vaya a comparar dos o más grupos, tambien es importante que las desviaciones estándares, o en otras palabras, la variación de sus datos en cada grupo sea aproximadamente similar, esto se puede verificar con el test de Bartlett, o a «ojo» viendo que una desviación estándar NO sea el doble de otra.
Referencias bibliográficas
- Rimmm AA. et al. Basic Biostatistics in Medicine and Epidemiology. Appleton-Century-Crofts,New York, 1980: 37.
- Snedecor GW, Cochran WG. Statistical methods. 7th. ed. Iowa press, Ames,1980:39-51.
Retroalimentacion
1. ¿Cuáles son las principales características de la distribución normal ?
2. ¿Qué es la escala de valores z ?
CICLO DE PRACTICA III
INFERENCIA ESTADISTICA
Procedimiento por medio del cual se llega a inferencias acerca de una población con base en los resultados obtenidos de una muestra extraída de esa población.
TEST T (ver el apunte de test t en otra unidad).
Se hará este test cuando tenemos dos grupos, con datos que tienen distribución normal (demostrarlo, por ejemplo, con test de Shapiro-Wilks), puede ser pareado o no pareado.
Para probar la hipótesis, existen diferentes métodos estadísticos. El principio básico es determinar qué nos están tratando de decir los datos. En la mayoría de los trabajos de investigación donde la variable en estudio es intervalar, la desviación estándar de la población es desconocida y debe ser estimada de los datos.Cuando la ds es desconocida, usamos el test t (también conocido como test de Student) para probar la hipótesis Ho : m1 = m2 (promedio del grupo 1 = promedio del grupo 2). La estádistica t es similar a la estadística z. Su distribución tiene forma de campana y es simétrica, como la distribución normal, pero es más achatada. El parámetro utilizado para describir la distribución t es el grado de libertad, donde:
Grados de libertad (gl) = tamaño de la muestra (n) – 1.
Comparación de dos muestras, test t no pareado:
Hipótesis de nulidad Ho :
m1 = m2
 Calcular t para test t no pareado con esa fórmula (s es la varianza al cuadrado de cada grupo, fórmula más fácil). Si mezlca varianzas use esta otra fórmula:
Calcular t para test t no pareado con esa fórmula (s es la varianza al cuadrado de cada grupo, fórmula más fácil). Si mezlca varianzas use esta otra fórmula:
 (varianza mezclada) Grados de libertad gl = n1 + n2 – 2
(varianza mezclada) Grados de libertad gl = n1 + n2 – 2
En el test t la distribución de la población de donde se tome la muestra debe ser normal. Si no se cumple con esta condición los datos deben ser ordenados y analizados con los métodos sugeridos para variables ordinales.
El test t pareado se utiliza en los estudios en que se tienen dos mediciones en los mismos individuos. Se utilizan entonces, pares de observaciones. Grados de libertad, n – 1.
 d = diferencia promedio
d = diferencia promedio
gl = n – 1
Referencias bibliográficas
- Glantz SA. Primer of Biostatistics. 3rd ed. McGraw Hill, New York, 1992:67.
Retroalimentación
- ¿Cuándo puede utilizar el test t ?
- ¿Qué características deben tener las observaciones para poder utilizar el test t?
CICLO DE PRACTICA IV.
ANALISIS DE VARIANZA (ANOVA) (ver unidad de análisis de varianza)
Es una técnica mediante la cual la variación total presenteen un conjunto de datos se distribuye en varios componentes. Asociada concada uno de estos componentes hay una fuente específica de variación,de modo que en el análisis es posible averiguar la magnitud de lascontribuciones de cada una de estas fuentes a la variación total.
El análisis de varianza se utiliza con dos fines distintos: 1)estimar y probar las hipótesis acerca de las varianzas de las poblacionesy 2) estimar y probar las hipótesis de las medias de las poblaciones.
Se utiliza para el análisis de variables intervalares, de 3 ómás grupos. En el siguiente ejemplo tres estudiantes (1, 2 y 3)obtuvieron las siguientes notas en cuatro asignaturas (asignaturas : a,b, c y d):
| asignatura | ||||
|---|---|---|---|---|
| alumno | a | b | c | d |
| 1 | 5 | 5 | 4 | 6 |
| 2 | 6 | 4 | 5 | 4 |
| 3 | 7 | 5 | 3 | 6 |
| åx2 | 110 | 66 | 50 | 88 |
| åx | 18 | 14 | 12 | 16 |
| promedio | 6 | 4.6 | 4 | 5.3 |
n = 12
nr = 3 (número de filas)
nj = 4 (número de columnas)
 STC: suma total de cuadrados
STC: suma total de cuadrados
WSS: suma de cuadrados dentro de los grupos
BSS: suma de cuadrados entre los grupos
Con estas fórmulas encuentre los valores y se construye la Tabla de Anova:
| Origen de la variación | Suma de cuadrados | Grados de libertad | Cuadrados Medios | Valor F |
| Entre | 6.66 | 3 | 2.22 | 2.42 |
| Dentro | 7.34 | 8 | 0.918 | – |
| Total | 14.00 | 11 | – | – |
En esta tabla: cuadrado medio entre los grupos = suma de cuadrados / grados de libertad ó sea: 6.66/3 = 2.22.
También cuadrado medio dentro de los grupos = suma de cuadrados / grados de libertad, 7.34/8 = 0.918.
Finalmente el valor de F = Cuad.Medio entre / cuad.medio dentro = 2.22 / 0.918 = 2.42
- Grados de libertad, entre los grupos = nj – 1=3
- Grados de libertad, dentro de los grupos = (nj) * (nr- 1)=8
- Grados de libertad, total = (n – 1) = 11
- Cuadrados medios = suma de cuad. / grados de libertad
- Valor de F = cuad medios entre / cuad. medios dentro
De acuerdo a los grados de libertad 3 y 8 se obtiene en la tabla de valores de F, el valor crítico, que en este caso para p<0.05 es 4.07. Como el valor obtenido es menor, no existen diferencias significativas (se acepta la hipótesis de nulidad), entre las notas obtenidas por los alumnos en las cuatro asignaturas. Si hubieran existido diferenciassignificativas se necesita saber entre qué asignaturas y para esto deberá realizarse otro test estadístico, para la comparación de múltiples promedios, entre los cuales están: test de Tukey, Scheffé y otros los cuales puede consultar en alguna de las referencias citadas.
Análisis de regresión lineal
Se asume que las variables son dos,con distribución normal, intervalares, una dependiente (eje Y) otra independiente (eje X). Se utilizan las siguientes fórmulas (ver también ejemplo 3). El propósito de la regresió lineal es.



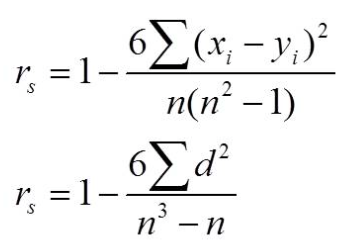 (r: correlación de Pearson
(r: correlación de Pearson
rs: correlación de Spearman,para variables ordinales o intervalares que no tienen distribución normal)
En el análisis de regresión lineal se asume que debe cumplirse con los siguientes requisitos:
4. Homocedasticidad (La varianza de Y es la misma para cualquier X).
5. Distribución normal (Para cualquier valor de X, Y tiene distribución normal).
En caso que la variable intervalar, dependiente o independiente, o ambas, no tienen distribución normal, se debe realizar solamente correlación de Spearman que también se utiliza en caso de variables ordinales.
Referencias bibliográficas
- Daniel WW. Bioestadística. Base para el análisis de las cienciasde la salud. Limusa, México, 1989:283.
- Glantz SA. Primer of Biostatistics. 3rd ed. McGraw Hill, New York, 1992:67.
- Rimmm AA. et al. Basic Biostatistics in Medicine and Epidemiology. Appleton-Century-Crofts,New York, 1980: 37.
- Snedecor GW, Cochran WG. Statistical methods. 7th. ed. Iowa press, Ames,1980:39-51.
Retroalimentación
1. En el ejercicio de ANOVA ¿cuál es la hipótesis de nulidad?
2. ¿Cuándo puede utilizar el ANOVA ?
CICLO DE PRACTICA V
CHI-CUADRADO (ver unidad de tests no paramétricos)
Para el análisis de estudios de variables nominales se utilizan test no paramétricos. El chi- cuadrado se aplica en tablas de contingencia de 2 ó más entradas, y el valor de cada celda debe ser mayor a 5 (si los valores son menores, se puede utilizar la correción de Yates, o el test exacto de Fisher). Tabla de contingencia se refiere a colocar los valores observados en filas y columnas, de forma de tener en una tabla el total de individuos en cada categoría.
Ejemplos:
Para saber si un dado está cargado, lo arrojamos 60 veces, obteniendo las siguientes observaciones (O):
cara 1 7 veces
cara 2 5 veces
cara 3 15 veces
cara 4 17 veces
cara 5 5 veces
cara 6 11 veces
Lo esperado (E) es que cada cara del dado hubiese aparecido igual númerode veces, en este caso 10. Por lo tanto la hipótesis de nulidaddice que la frecuencia de aparición es igual.
Al aplicar chi-cuadrado:
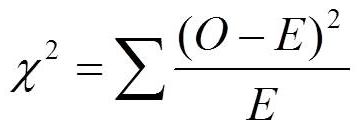 = 13,4
= 13,4
Grados de libertad gl = nf – 1 = 6 – 1 = 5
En la tabla de valores de chi cuadrado el valor crítico para p<0.05, con cinco grados de libertad es 11.07, por lo tanto se rechaza la hipótesis de nulidad y se acepta la hipótesis alternativa, el dado está cargado.
Referencias bibliograficas:
- Glantz SA. Primer of Biostatistics. 3rd ed. McGraw Hill, New York, 1992:133.
Retroalimentación
1. Construya una tabla de contingencia en base a observaciones odontológicas.
2. Qué tipos de variables pueden ser analizadas mediante chi cuadrado?
Fórmulas para pruebas de bioestadistica
 |